My Big Data Academy Experience
My Big Data Academy Experience
I'm Mary-Jane, and I joined Kainos in 2017. I recently changed the course of my career by completing the Big Data Academy at Kainos and wanted to share my experience with anyone who might be considering applying next time.
Why Data Engineering?
I'm not one to shy away from my weaknesses, but rather seek to improve them in whatever way I can.
A couple years ago I didn't think I'd ever have the technical skills or logical problem-solving ability to become a data engineer, that's something really smart people who are maths geniuses do, right? But I decided that 2019 was the year I would conquer my fear of data, and all the functional, mathematical thinking that goes with it.
I had tinkered with some machine learning tools in 2018 during my time in the Kainos Applied Innovationteam but one thing that I kept stumbling upon was the challenge of data. There was either not enough of it, or too much of it and it wasn't being managed well.
Identifying this problem left me keen to work towards solving it.
When I heard about the Kainos Big Data Academy, I had to apply and luckily for me, I was successful!
What is the Big Data Academy?
I'm not going to go into too much depth about the tools we learned, I think that's deserving of another blog in itself, but here's a quick overview of the specific tools we learned:
- Hadoop - a framework for processing distributed data, including HDFS, which stands for Hadoop Distributed File System
- Impala - like Hive, it provides a SQL-like interface for interacting with distributed data??? ??they both have separate pros and cons
- ElasticSearch - a search engine for distributed data based on the concept of inverted index
- Kafka - no, not the famous novelist Franz Kafka, but rather a high-throughput messaging system with producers and consumers that enables the processing of streaming data

- Spark - a framework for programming applications that interact with distributed data
- Scala - based on Java, Scala is a functional programming language with concurrency built into its core, which is what makes it ideal for working with distributed data
- We also learned more advanced concepts in Spark such as Spark Streaming/Structured Streaming
These were the formal lessons we learned, but there were other things we picked up along the way. Particularly in the four-week internal project?
Practice Makes Perfect
It's hard to really understand new skills or tools and how they all fit together until you've actually implemented them in a real project.
This is why the bulk of the Big Data Academy is an internal project where you can practice all you've learned and see how they can be applied in the real world.
Our internal project was a proof of concept application designed to process thousands of transaction data per second.
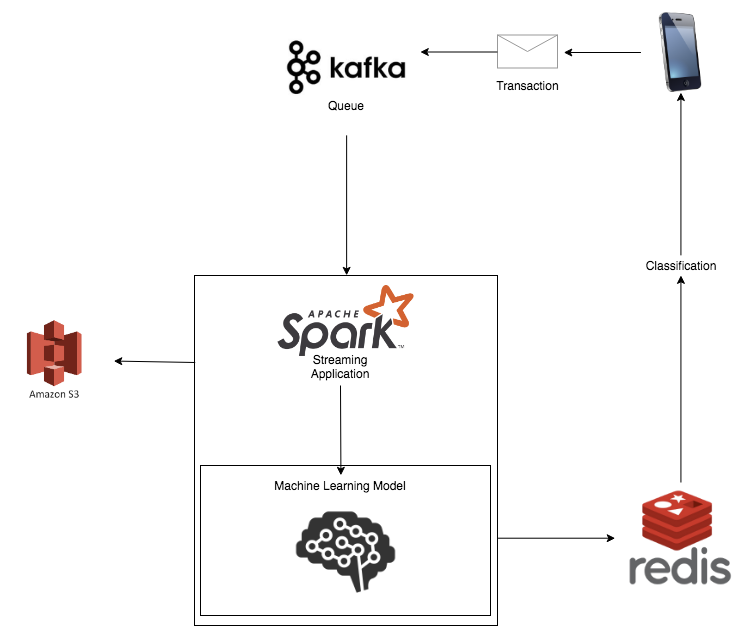
There were other skills I picked up during the project that weren't formally taught and I didn't have prior experience with, such as:
- Setting up continuous integration with Jenkins
- Setting up and running distributed applications on different cloud services
- Integration testing with Docker (side note: Kitematic is great if you've never used Docker before)
- Working with different types of data storage, such as S3 & Redis
- Even some front-end development with Scala Play to demo our finished data pipeline in a visual way

What's not mentioned, but definitely should be, is the mentorship and guidance you get throughout the academy. I was a software engineer before I started, but we also had technical architects on the academy. With the years of experience of the technical architects (both technical and communication/teamwork), their support through pair programming, code reviews, retrospectives, and feedback was my favourite part of the internal project.
Why is Kainos Interested? ?
Aside from the fact that Kainos invests a lot into the education and enhancement of their employees, as well as the local community, there is a dedicated Data & Analytics Capability at Kainos, which enables them to offer this as a service to their clients.
Digital Transformation requires data & analytics in order to be truly transformational.
Growing this capability allows Kainos to seize more opportunities.
Is Data Engineering For You?
Don't be intimidated by the technologies or by a lack of maths in your background. If you enjoy a challenge and want to learn a whole new suite of technologies, then data engineering might be for you! And what better way to learn than with the fantastic training and support of the Big Data Academy at Kainos.
Find out more about Data careers at Kainos, whether you're a grad or a seasoned professional!