Driven by Reinforcement Learning - a day at AICamp
Driven by Reinforcement Learning - a day at AICamp
At this year's Kainos AI Camp in Belfast and Birmingham, the Applied Innovation team worked with some staff from AWS to deliver two DeepRacer Day Workshops at the camps!
AICamp is a two-week long camp full of theory, workshops and practical sessions to give students a strong introduction to the field of artificial intelligence and machine learning, and how it is being used to benefit our everyday lives.
This year, two days of each camp were dedicated to AWS; the first covering AWS SageMaker and deploying machine learning models. The second day was a workshop and racing day for the AWS DeepRacer ? teaching students about applications of AI models, reinforcement learning and getting some competitive spirit going before the hackathon that's at the end of AI Camp.
What is the AWS DeepRacer?

A fully autonomous 1/18th scale race car driven by reinforcement learning, 3D racing simulator, and global racing league. Featuring a Linux distribution with enough computing power and storage to run a fairly intense reinforcement learning model at some consistent speeds, the car is built on top of a popular model RC racing car chassis.
After developing and training, the model is then downloaded to a physical car to be raced around a massive 8m x 4m track. We followed the AWS competition rules used for their racing events;
- You have four minutes on the track to complete as many laps as you can
- The fastest lap is your submitted time
- Come off the track and your racer is placed where it came off
- Come off the track three times and your lap is marked as 'Did Not Finish'

Using the AWS Console you can develop reinforcement learning models for the car and train them by setting the model to race around a simulated track for a few hours. The racers are aimed not only at just their racing competition, but they're also for education, mostly on how reinforcement learning works and its applications. For both of our events, we started with some refreshers on different aspects of machine learning before covering what exactly reinforcement learning is, with the model building acting as the exercise to reinforce what they've learnt.
If you want to build some models or are interested in how it works, here are the basics of Reinforcement Learning that we covered with the students;
Reinforcement Learning
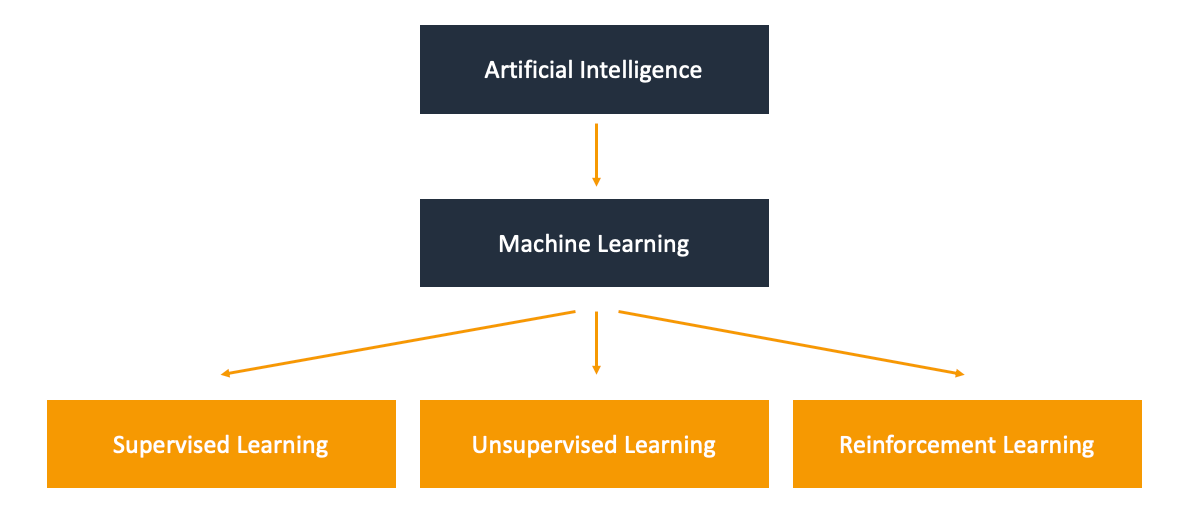
If we look at Artifical Intelligence as an umbrella term, one of the biggest aspects under it is Machine Learning, which is often divided down into Supervised and Unsupervised Learning. Reinforcement learning is often forgotten in place of its more popular siblings, but still merits itself a category of its own for being somewhere between Supervised and Unsupervised.
The quote AWS gives us is;
Reinforcement learning, in the context of artificial intelligence, is a type of dynamic programming that trains algorithms using a system of reward and punishment
AWS DeepRacer Training
To break that down; a reinforcement learning algorithm, or agent, learns by interacting with its environment. The agent receives rewards by performing correctly and penalties for performing incorrectly.
The agent learns without intervention from a human by maximizing its reward and minimizing its penalty.
To explain that further, let's take the example of a robot jumping over some obstacles; first, you could give the robot the ability to jump at various distances while approaching an obstacle.
For the first test, let it jump either 2 metres away, 1 metre away, half a metre away, or even 0 metres away which causes it to crash into the obstacle before actually launching upwards.
After a lot of trial and error with when to jump, the robot will eventually learn that it will receive a point by jumping just before hitting an obstacle (say 0.5 metres) ? because jumping then leads to a successful clearing of the obstacle.
 The DeepRacer Console
The DeepRacer Console
To autonomously race the car you have to develop and train your own machine learning model, to do this you have to use the AWS DeepRacer console. There we are given a model that we can shape various aspects of, mainly the reward algorithm, hyperparameter tuning and the action space. The amount of options for this leads to an impossibly large number of possibilities of configurations for the model.
The reward algorithm lets you punish or reward the car encouraging it to complete the track in faster times, the variables you can control for this are the parameters that the car can measure. There's a load of these parameters, most are self-explanatory aspects of the car and this diagram helps capture exactly how all of them relate to the car:
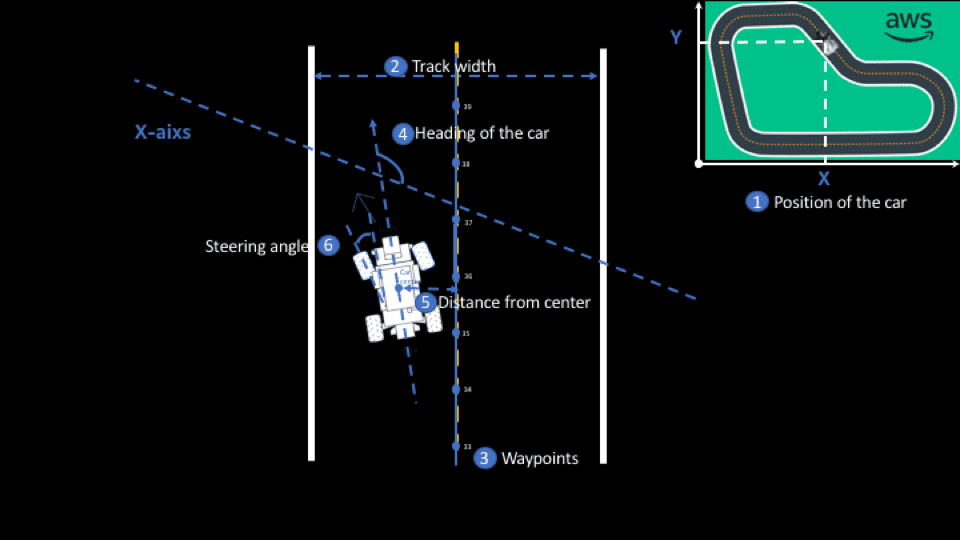
We took the students through each parameter at the time but a handy online resource, that the AWS team pointed us to, explained all the parameters that the DeepRacer has and how reinforcement learning applies to it. Find it here!
The hyperparameters offer a range of different options for tuning the model for the DeepRacers. We covered what each of them meant with the students but the important thing for them to know is how they can change your reward algorithm. Most people find that through trial and error, cloning, and retraining models ? they can discover what seems to work best for a given model.
 simulated environment of the track with a physics engine acting of every aspect of the car and track to try and best represent the real track. The model is set up to run in this environment for hours on the track and learn over a time that we have specified up to 8 hours.
simulated environment of the track with a physics engine acting of every aspect of the car and track to try and best represent the real track. The model is set up to run in this environment for hours on the track and learn over a time that we have specified up to 8 hours.
Once a model is trained, we can evaluate its performance by racing it on a simulated track, giving us some rough times for its performance and how much of the track it was able to complete. If the digital car completed at least one lap of the track then we downloaded the models and got ready to race them on the non-digital cars!
Racing In Belfast
After uploading the models to the cars we were able to set them off on the track and get them racing, below are some shots of the students, the cars racing, and their reactions:
















We got some great times with the winner hitting a time the AWS staff said would've placed at the AWS London Summit a few months before!
Racing In Birmingham
After a short break, we were back racing, this time in Birmingham! Again we took the students through all the theory, building models and then getting ready to race!
Below we've got some photos and videos of the cars racing at the Birmingham AI Camp:















After challenging the students to try to beat the great times in Belfast, they didn't let us down, we got a blazingly fast time of 8.72 seconds. It was the fastest the AWS staff had seen in person, never mind placing in London as the Belfast model would've, they said that time would've won.
Both sets of campers really enjoyed the events and got super competitive with it all, they all went to complete the rest of AI Camp and its hackathon. But after running both sessions we learnt some lessons for competing with our own models in future!
Tips & Tricks
So from running both camps and speaking to the team we definitely got some tips we want to pass on to you;
This first once might seem obvious for someone who's used to machine learning concepts, but you need to build your models to generalise ? be wary of convergence;
Training time is an important thing to keep in mind with convergence, training for a maximum of 8 hours, cloning it, and running it again doesn't normally lead to an effective model. Typically you see much more success with smaller training increments of 1?�2hours before cloning and tweaking the hyperparameters.
Next up is analysis; the DeepRacer console is useful but digging deeper into the training and evaluation logs is where you can start to see exact points causing you problems and start shaving vital seconds off your lap times. These two GitHub repos, here and here, proved to be extremely useful in building our own models and allowed us really to get 'under the hood' of the DeepRacer.
And finally, keep in mind the actual real-world limitations of the car when building your models ? these cars have computational limits that the simulator doesn't. The training simulator can pass far more complex reward functions than the DeepRacer itself can. It's also worth saying some aspects of the model, i.e. waypoints, just don't exist in the real world and accuracy in the model evaluation won't reflect when you try it on the track.
An indispensable resource for taking your models further is the Deep Racer Community, this website and associated Slack group is a gold mine of tips and tricks. It includes topics for everything, including how to train models offline and avoid those large training bills!
That's all!
We're going to take everything we learnt to start building our own models before we head back out to the track but for all of you its time to get started.
Here's the landing page for the AWS DeepRacer Console, there are prizes for the virtual leagues and the community leagues if you can't make it to an AWS Summit ? happy racing!
Interested in AI Camp? Find out more and sign up for updates here!