Lightweight architectures for integration projects
Lightweight architectures for integration projects
Organisation transformation often results in large software integration projects, which include several systems exchanging data to provide proper services to users. While on the surface, this may seem to be a technical challenge, the main problems lay outside of pure point-to-point data exchange. They are related to organisation structure and delivery maturity, which can vary between different parts of the system.
One of the typical approaches toward solving complex integration problems is the introduction of ESB (Enterprise Service Bus). Open source or proprietary integration engines like ESBs cover the technical aspects of the solution including message/request routing, data transformations, error handling and monitoring. The ESB is configured, extended and managed by a central team. It becomes the heart of the integrated system.
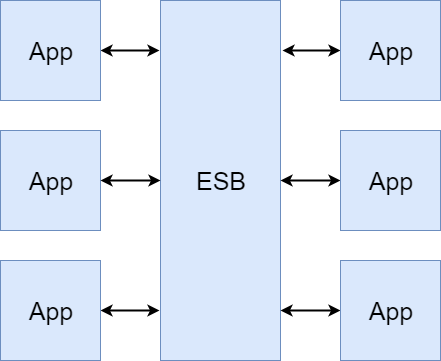 provide several benefits, but it may defeat the effectiveness of delivery by creating a single point of failure, and the bottleneck for delivery as a central team controls the way software is developed and released.
provide several benefits, but it may defeat the effectiveness of delivery by creating a single point of failure, and the bottleneck for delivery as a central team controls the way software is developed and released.
Key challenges in integration
- Domain model complexity and functional limitations of the apps Calling the endpoint which is exposed through REST, SOAP or other protocol is usually a simple activity but how do you ensure that all applications are working correctly in the environment? The data may be passed through synchronous, asynchronous and batch processes. It can be produced/consumed through different channels at the same time. Solving technical challenges around integrations does not ensure that apps will behave correctly. The flow of the data throughout many systems may have surprising results.
- Environments
Building large environments which include all of the components is not cost-effective and requires significant effort in order to manage it. Strong centralisation results in high coupling. You end up building more and more environments and coordinating deployments. - Test data
With complex domains like financial, healthcare or business-sensitive information, it's very challenging to create good test data sets. Many issues that are showing up during integration or testing are not related purely to interface specification but the data caveats which are not defined at the interface level. - Vendor/department defensiveness
In many situations, the transformation of the organisation may require work in a hostile environment with conflicting interests. It's vital to create a shared goal and understanding. The problem to collect test data or connect to the particular service may be far from a technical one. The priority of the project may not be shared between parties. - Quality Assurance
Complex work environments have a significant impact on testing. The QA process is deferred and executed on a unified, integrated environment. The common agreement is that the sooner you catch the issue, the cheaper it is to resolve it, so lack of good early tests results in many issues during the end-to-end integration and slowdowns the delivery. Coupling between systems, teams and releases have a severe impact on the cycle time and overall quality. - Software releases
Each component which is part of the integration will have its own release lifecycle and versioning scheme. Releasing software is hard, and integrated systems suffer from higher complexity. Failures to release software result in practices which do not solve the problem: more control, more coordination, scheduled releases. It means that you will go as fast as the slowest link.
Conway's law?? ? ?? understanding communication
The list of challenges is not extensive, and we could dive into a discussion about error handling, transactions, security, synchronous vs asynchronous data exchange or protocols but at the very basic level you should start with the organisation and not with the software.
"Organizations which design systems ? are constrained to produce designs which are copies of the communication structures of these organizations."
Melvin Conway
I could take any project I worked on in the past and decompose some design decisions which were clearly a result of the intra-organisation communication chain. ESB is an example of such a solution where you have disconnected systems managed by departments in isolation, and you put a central team which is supposed to connect them. This kind of approach won't handle the challenges that you will see on the way.
Only organisation shift will allow you to achieve your goals fully.
What does good look like?
There may be specific reasons to use products like ESBs or specialised integration engines, but they tend to solve technical problems while reinforcing challenges at the organisation level. Integration is never a plug and play activity. If you create a work environment which is highly controlled and there is high coupling between the teams, the chances that the project will fail are greater.
Now let's look on it from a different perspective. What does good look like?
You want to have stable environments with a clear path to production.
The maturity/quality of each application will differ. You can encounter all kinds of limitations from lack of knowledge, inadequate licensing, lack of any CI/CD pipelines or even basic tests. It is not reasonable to assume that all of those issues will be resolved. It will be the opposite situation, and those issues at the service level will amplify the problems during integration.
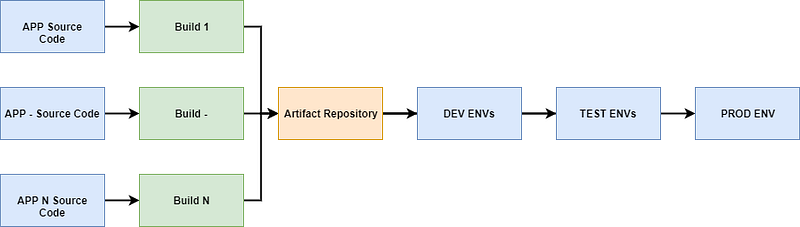 Stability patterns which are very popular in microservice architectures will protect the integration engine or point-to-point integration against cascading failures. This is good enough to handle error situations gracefully, but normal operation requires processes that decouple releases of features from the release of the particular component.
Stability patterns which are very popular in microservice architectures will protect the integration engine or point-to-point integration against cascading failures. This is good enough to handle error situations gracefully, but normal operation requires processes that decouple releases of features from the release of the particular component.
